
こんにちは、東京都内でしょぼいWEBディレクターをしています、当サイトの管理人の文鳥(@jishintaisakujp)と申します。
朝日新聞が国際問題に関する訂正記事などに検索回避タグを使った「朝日検索回避問題」が話題になっていますが、そもそも「検索回避タグって何?」という方もいらっしゃると思います。これは一言で言うと「逆SEO」なのですが、その辺についてなるべく初心者の方にも分かるようにざっくりと紐解いていきたいと思います。作業ミスなのか故意なのか、よくおわかり頂けると思います。
さすが天下の朝日新聞!朝日新聞が行っている逆SEOとは何かを掘り下げてみる(朝日検索回避問題)
逆SEO(リバースSEO)とは
逆SEOについて説明するには、SEOは何かというお話からさせて頂きます。
SEOは、Search Engin Optimaizeの略で、検索エンジン最適化と訳します。GoogleやYahoo!、Biglobe、docomo/au/softbankなどの大手ポータルサイトのネット検索機能の殆どはGoogleの検索エンジン(ネット検索システム)を使用しています。大手でGoogleを使っていないのはマイクロソフトのBingくらいかな。つまり実質上、検索エンジンはGoogleの独壇場です。
Googleの検索エンジンはある意味人工知能AIのようなもの。Googleに気に入られるようなWEBサイトが、ネット検索したときに上位表示されます。
普通の人は検索ページの上の方しか見ませんから、WEBで情報発信したい企業や人は、なんとかしてGoogleの検索エンジンに気に入られるようなサイトにします。ざっくり言うと「Googleに対して最適化する」、これがSEOです。
逆SEOとは、細かくは後述しますが上記SEOの逆をやることです。逆SEOでは、とことんGoogleに嫌われるか、Googleに「このサイトは検索対象から外して下さい」とサイトに記述します。リバースSEOなどともいいます。
それではなぜ逆SEOする企業があるかです。せっかく自社のWEBサイトをネット検索されたくないという理由とは何なのでしょうか。逆SEOはなにも朝日新聞に始まったことではありません。よく聞かれるのが美容・医療・健康志向系の企業サイトです。
現在のネット社会では。WEBサイトに掲載する情報はリアル店舗と同等、もしくはそれ以上の影響力があります。特に美容・医療・健康志向系の企業サイトでは、健康被害の観点や各種法令から、宣伝及び営業行為だけでなく、副作用などのデメリットやリスクも必ず記載すべきとされています。そういったサイトページ(以下「ネガティブページ」)は存在しないと批判の対象にもなりますし、場合によってはお役所なんかから指導が入ったりします。
でも企業側からしたらネガティブページが目立ってしまっては営業に支障が出ますよね。そこでネガティブページに対して逆SEOをかけるわけです。サイトページが存在しないわけではないという体裁を保つ一方で、Googleなどの検索サイトからでは極めて探しにくいようにするのです。
あとは反社会的勢力と呼ばれる団体や、詐欺又は詐欺に限りなく近い団体などが逆SEOを行います。騙したい相手以外にサイトを見られては都合が悪いからです。
つまり逆SEOってのは、けして違法ではないのかもしれないけど、消費者からしたら不誠実極まりないって話ですよね。これを国内最大手の報道機関である朝日新聞が現在も行っていることが非難を浴びています。いわゆる「朝日検索回避問題」です。
ちなみにSEOを推進するにあたり、ノイズになるサイトページに逆SEOをかける場合もありますが、真実を伝えるべき報道機関がネガティブページは消費者に伝えないでいいんかい、って話に戻ります。
逆SEOのやり方
逆SEOはSEOと似ています。繰り返しになりますが、逆のことをすればいいのです。
まず前提として、SEOには、サイト自体に対策を行う内的SEOと、他のサイトを利用して行う外的SEOがあります。
外的SEOは良質なサイト、例えば人気のあるサイトや公共機関のサイトからのリンクをたくさん得ることで、「このサイトは良質な注目を浴びている」とGoogleが判断して検索上位に表示されやすくなるものです。基本的にサイトページだけでなくサイト全体が対象となります。
「外的逆SEO」をやるとしたら悪質なサイトからのリンクをたくさん得るように仕掛けます。例えば、過去にスパム行為を行ったことのある中古ドメインを大量に買い、そのドメインでWEBサイトを量産して、ネガティブページに対してリンクを張るのです。
ただし、外的逆SEOをかけようとするとネガティブページだけでなく、サイト全体のGoogle評価が悪くなる可能性があり本末転倒となり、現実的に行われることはありません。本体とは別のサイトにネガティブページを立てる場合はこの方法が有効ですが。
そこで逆SEOをするなら内的逆SEOとなります。内的逆SEOを説明するのに、やはり通常のSEOの一般的なやり方と比較して説明します。
1.サイトページ内のHTMLソースを適切に記述する。
①メタタグ(robots)
ブラウザでサイトページを開いた状態で右クリック(Macの場合はcontrolを押したままクリック)して「ページのソースを表示」を行うと表示されるのがHTMLソースです。Googleはこの内容を読んで「良質なページかどうか」と「検索対象に含めたりインデックス(Googleに記録)等してもいいか」を判断します。
前者は割愛するとして、後者に注目します。
Googleなどの検索サイトで検索できるようにするにはそのページをGoogleへ記録(インデックス)しなければ始まりません。そこでGoogleの巡回ロボット(クローラー)がそのサイトを見に来たとき、「このサイトをインデックスしてね。このページからのリンクを辿って評価してね。」とGoogleに伝えるのが一般的です。このように記載します。
<meta name="robots" content="index, follow"/>
逆SEOするには「このページをインデックスしないでね。このページからのリンクを辿らないでね。このページを検索エンジンに保存しないでね。」とGoogleに伝えます。このように記載します。
<meta name="robots" content="noindex, nofollow, noarchive"></meta>
朝日新聞は、「訂正・おわび」ページにもこのタグが書かれています。なぜ?
また朝日新聞は、慰安婦問題について吉田証言が誤りだったことを認めた英語版ページに対して、この逆SEOを行いました。なぜ英語版ページなのに日本語サイト内にあるかが謎ですが。きっと英語版サイトに載せて世界中に発信したくない事情があるのでしょう。
https://www.asahi.com/articles/SDI201408213563.html
朝日新聞は多くの方から指摘を受けてnoindex, nofollow, noarchiveは外しました。朝日新聞の言い分としては「記事に検索回避タグを設定し、社内の確認作業を経たのちにこのタグを解除して一般公開しましたが、このうちの2本で設定解除作業の漏れがあった」とのこと。
https://www.asahi.com/corporate/info/11773746
はっきり言う。ウソをつくな。
普通は、非公開のテストサーバにアップして社内確認し、問題なければ本番サーバにファイルをコピーして本番公開を行います。その際にタグを変更する=ソースをいじることは、技術者的にはリスクでしかないため絶対に行いません。そもそもテストサーバは非公開ですからnoindex, nofollow, noarchiveを書く必要がないのです。
またこれは推測ですが、朝日新聞のような大規模ニュースサイトの場合は、CMS(Contents Management System)という記事管理とWEB更新のできるシステムを使っているはずです。WordpressやMovableTypeよりも遙かに巨大なやつです。百歩譲ってhtmlをちまちま書いてFTPでアップする手動更新なら仰るようなミスは可能性はありますが、CMSを使っているならばわざとそうしない限り起こりえません。毎日大量の記事をさばいているのですから自動化しているはずだからです。
考えられるとしたら、そのCMS管理画面の記事管理ページで、メタタグチェックみたいなものがあり、デフォルトが「noindex, nofollow, noarchive」になっていて、それの外し忘れでしょうか。
でもそうだとしたら、26年8月5日付の朝日新聞デジタル「『挺身隊』との混同 当時は研究が乏しく同一視」は掲載後から検索回避タグが張られていたことが分かっていますが、これはどう説明されるのでしょうか。
https://www.sankei.com/world/news/180909/wor1809090002-n1.html
慰安婦問題について吉田証言が誤りだったことを認めた英語版ページに話は戻り、noindex, nofollow, noarchiveは削除されましたが、
逆に普通はあるべきindex, followが書かれていません。なんで?まだインデックスされちゃ困るの?
ちなみに産経新聞は訂正記事にもnoindexは書いていません。報道機関のサイトはこうあるべき。更新する可能性があるからnocacheが書いてあるのは当然。
https://www.sankei.com/affairs/news/180208/afr1802080005-n1.html
②メタタグ(Googlebot)
SEO的には基本的に逆効果なのであまり使わないのですが、朝日新聞のサイトで多様されているタグをご紹介します。ほぼ全てのニュース記事に以下のようなタグがかかれています。
<meta name="googlebot" content="unavailable_after: 20-Sep-2019 05:00:00 JST" />
これは「Googleさん、2019年9月20日以降は見に来ないでね、そんでGoogleさんにインデックス登録されていたらこの日の翌日に消しといてね」という意味です。つまり2019年9月20日以降はGoogleなどの検索サイトにはひっかからないようにしています。
「有料の新聞を売っている新聞社としては、無料で記事を掲載するサービスは1年限りですよ。データも大量になるから長期間保持できないよ。」ということなのでしょうが、国際問題にまで発展しているようなことまで訂正記事を1年で打ち切るのはいかがなものでしょうか。誤った情報はずっと残るのに。
例えば、産経ニュース2017.8.1付け「朝日新聞が訂正・おわび 終戦引き揚げ女性の「中絶手術」に関する読者投稿で」https://www.sankei.com/west/news/170801/wst1708010051-n1.html
にて紹介されている、6月19日付「引き揚げの女性に中絶手術」の内容についてお詫びと訂正記事を出したとありますが、朝日新聞サイトでは既に見ることができなくなっています。
って、上記吉田証言については指摘を受け、もはやギャグのような2100年12月1日に修正されました。タグを消しても角が立つから100年後にしちゃえ!みたいな?
https://www.asahi.com/articles/SDI201408213563.html
2.トップページに見せたいページのなるべく上の方にリンクを書く
諸説ありますが基本的にGoogleはページの上の方から読んでいきます。なので見せたいページ・見せなければならないページは、できればグローバルメニューと言われる、上の方のメニュー(朝日新聞なら「トップニュース」「新着」「天声新語」など)にリンクを書くのがSEO的にはベターです。あるいは見出し文言(hタグ)に書かれているテキストをGoogleは高評価します。
またGoogle先生は賢いので、人間が見て分かりにくい箇所のリンクやテキストはあまり評価してくれない(上位表示しにくい)とも言われています。そのため逆SEOをするならなるべく下の方に目立たないようにリンクを書きます。トップページなどにリンクを書かないのが逆SEO的にはいいのですが、書かざるを得ない場合はこうします。
朝日新聞では、かなり下の方に「訂正・おわび」があります。最初私はどこにあるか分からずにサイト内検索していました。まあ、お詫び訂正記事ページをグローバルメニューに載せたりhタグをつけたりすることは考えにくいのですが、それにしても分かりにくいのでURLをご紹介します。

3.適切なリンク導線を用意しておく
同じ階層にある読ませたいページが複数あるなら、それらを一覧表示したサイトページがあるべきです。Googleもそういった一覧ページから流入してインデックス或いは評価をしていきます。
しかし、朝日新聞の「訂正・おわび」ページは過去1週間分しか掲載していません。ひとつずつ開いていかなければならないというクソ仕様。WEBディレクターの一人として断言できますが、これはわざと使いにくく設計しています。利便性を考慮してのことであれば「過去のお知らせ」のように過去の訂正・おわびページ一覧があってしかるべき。
ちなみにサイト内検索で「=訂正・おわびあり」で検索するとようやく見ることができます。朝日新聞では訂正記事を出すとき、もともとの記事のタイトルに「=訂正・おわびあり」を追加して修正するからです。
https://sitesearch.asahi.com/.cgi/sitesearch/sitesearch.pl?Keywords=%EF%BC%9D%E8%A8%82%E6%AD%A3%E3%83%BB%E3%81%8A%E3%82%8F%E3%81%B3%E3%81%82%E3%82%8A&Searchsubmit2=%E6%A4%9C%E7%B4%A2&Searchsubmit=%E6%A4%9C%E7%B4%A2&iref=com_gmenu_search
4.サイトマップページに見せたいサイトページのリンクを書く
通常はサイトマップページというサイトの主立ったページを一覧表示したページを用意します。これは閲覧者の利便性だけでなく、このページをGoogleに対してインデックスしてもらうことでSEO的な効果が期待できます。
逆SEOをするなら、当然サイトマップにネガティブページのリンクを載せてはいけません。
朝日新聞では、http://www.asahi.com/sitemap/ にあります。
あれ?「訂正・おわび」ページがありませんね。見せたくないんですね。
5.Sitemap.xmlに見せたいサイトページのリンクを書く
GoogleのSearch Console(旧ウェブマスターツール)に「このサイトのサイトマップはこれですよ。こんなページ構成でサイト作ってるので見に来てインデックスしてくださいね」と伝えるためのファイルが Sitemap.xml です。
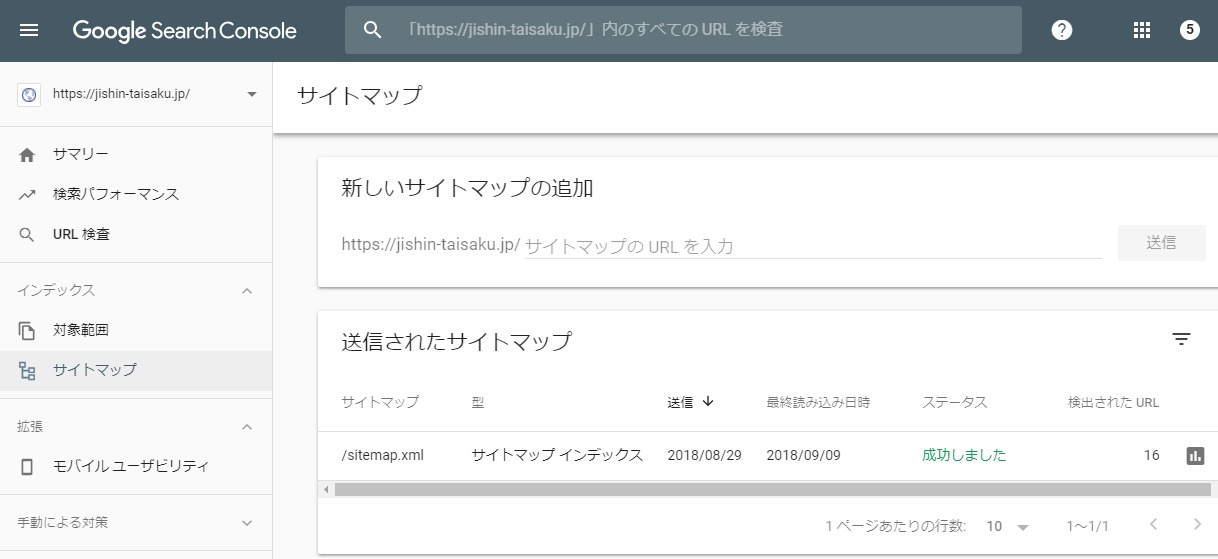
前述のサイトマップページには載せられないほどの大量のURLをGoogleに伝えることができる手段で、SEOの基本中の基本と言えます。最低限、トップやカテゴリートップ、サブカテゴリートップは必ず記載します。
朝日新聞のような規模のサイトでは、手作業でSitemap.xml を作ることは現実的ではなく、一定のルールに基づいてプログラムで自動生成して作られます。
逆SEOをするなら、当然サイトマップにネガティブページのリンクを載せてはいけません。
朝日新聞では、http://www.asahi.com/sitemap.xml などにあります。
あれあれ?「訂正・おわび」ページがありませんね。見せたくないんですね。
6.robots.txtを適切に書いて配置する
Googleなどの検索エンジンがそのサイトを見に来たとき、特定のフォルダやURLへのアクセス制御を行ったり、サイトマップファイルの位置を伝えるためのファイルです。トップページの直下にrobots.txtを配置します。
『「Disallow」は見ないでね、「Allow」は見てね、「sitemap」はサイトマップファイルがここにあるよ』というもの。システムフォルダとか廃止ページはアクセスしないでね、という一方、SEO的にはノイズになり得るカテゴリーページなどを記載することがあります。
朝日新聞では、https://www.asahi.com/robots.txt にあります。なぜか2009年3月5日の記事を2本除外している以外は特に変わったところはありませんね。この2本がどんな記事だったか気になります。お分かりになる方は教えて頂けると嬉しいです。
https://www.asahi.com/kansai/news/OSK200903050055.html
https://www.asahi.com//video/news/TKY200903050250.html
User-Agent: * Disallow: /video/news/TKY200903050250.html Disallow: /kansai/news/OSK200903050055.html Disallow: /travel/event/search/ Disallow: /science/index.html Disallow: /entertainment/index.html Disallow: /car/index.html Disallow: /housing/index.html Disallow: /showbiz/column/animagedon/index.html Disallow: /english/newsfeatures.html Disallow: /english/business.html Disallow: /english/cooljapan.html Disallow: /english/sports.html Allow: / sitemap: http://www.asahi.com/sitemap.xml sitemap: http://www.asahi.com/xml-sitemap-business.xml sitemap: http://www.asahi.com/xml_sitemap_politics.xml sitemap: http://www.asahi.com/and_M/sitemap.txt sitemap: http://www.asahi.com/and_w/sitemap.txt sitemap: http://www.asahi.com/ad/sitemap.xml
まとめ
SEOのベテランから言えばツッコミどころはあるかもしれませんが、ごく基本的なSEOは以上の通りで、そこから導かれる逆SEOについてご説明させていただきました。さすが朝日新聞。私が考えられる逆SEOは大体やってくれてました。
他にもGoogleのSearch Consoleを使えばSEOも逆SEOもできるのですが、サイト管理者当人にしか公開されないため今回は省略しています。
なお、当記事作成にあたってはネット情報も充分参考にさせていただきました。ありがとうございました。(事前許可いただいてます)
朝日がこれらの記事の英語版をWebサイト上でどう扱ってきたか時系列で纏めてみました。当時のページをwayback machineからキャプチャしましたが、ページレイアウトが崩れ当時のものと異なっておりますことをご了承ください。またクロールされていない日もあり日付は推測を含んでいます(日付はGMT基準) https://t.co/NqqGEC1c4U
— deno (@deno_denor) 2018年9月4日
誰かに「忖度」しているのか、人為的かつ作為的なメタタグの設定や、お詫び訂正記事の検索性の悪さが目立ちました。世論をも操作できるような大新聞社なのですから、基本的には「人間のやることだから誤報やミスもある」は通じないと考えます。それでも誤報をやっちまったときはその影響力の大きさを考慮して、誤報による誤解が解けるまで分かりやすく長期間において記事を掲載してもらいたいと思います。
また今回はあからさまだったので朝日新聞に焦点を当てましたが、ほかの報道マスコミのサイトについてもツッコミどころはありますので、改善いただきたいと考えます。今回の朝日検索回避問題をきっかけに消費者たちは目を光らせてますからね。報道の自由をうたうなら責任を持ってほしいものです。
だからといってブッチギリで朝日新聞がおかしいんですけどね。
以上。

